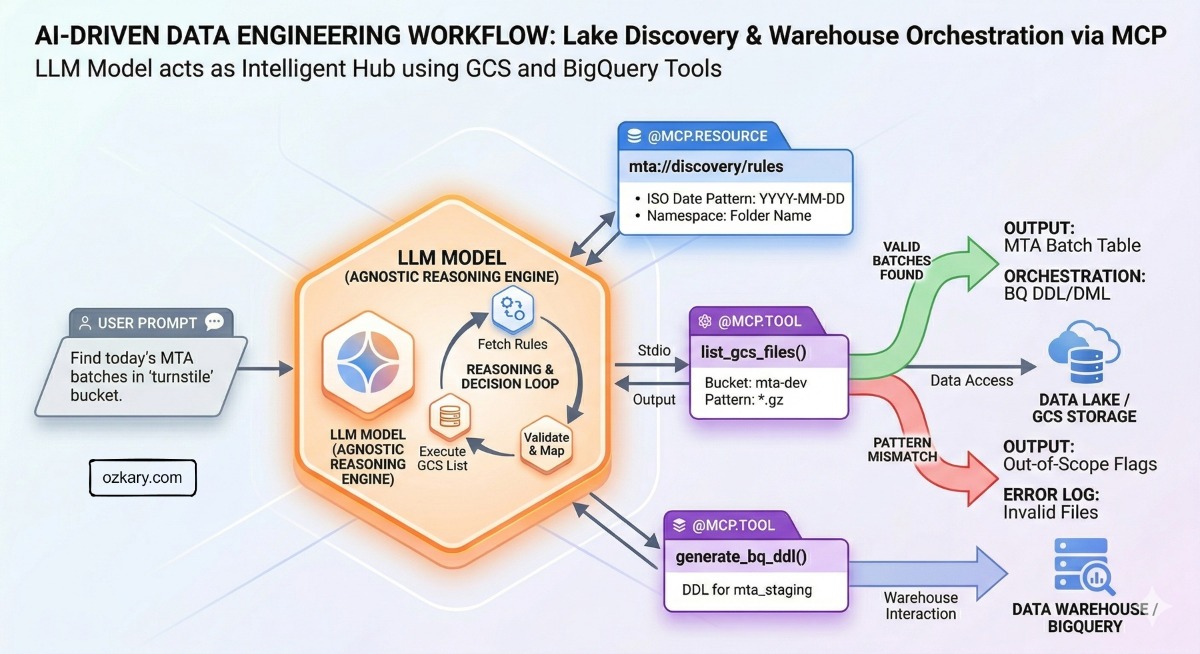
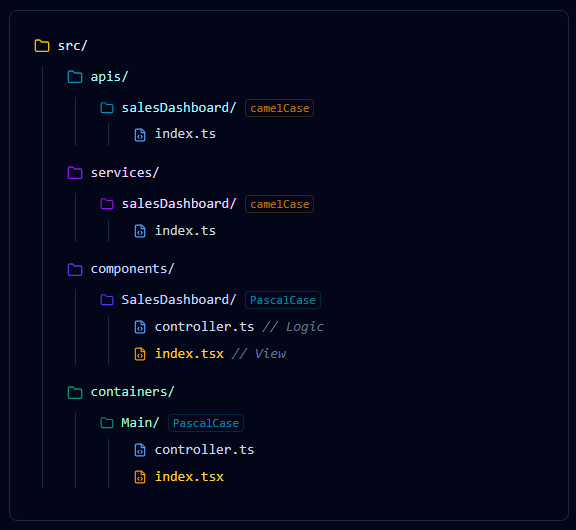
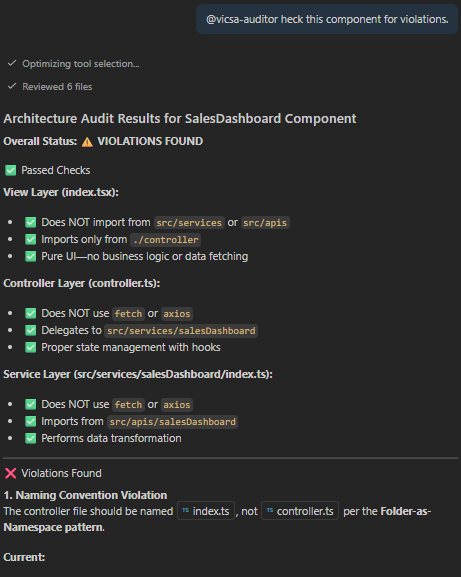
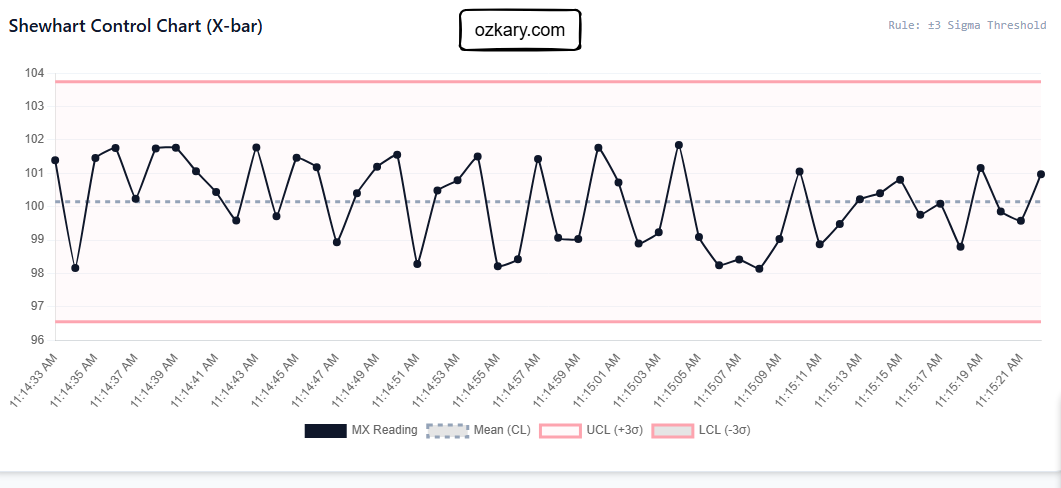
Overview
As the software development lifecycle shifts toward autonomous vibe coding, rapid AI prototyping, and Software Design Description (SDD) driven workflows, engineering teams face a critical structural bottleneck: the discovery and analysis gap. Generative AI tools excel at emitting syntactically valid code, yet they consistently fail when handed vague, ungrounded, or fragmented domain specifications.
To bridge the gap between initial domain exploration and deterministic engineering execution, I introduce AIStorming—a process-oriented framework born out of my engineering practice and foundational work in enterprise data pipelines and cloud-native application architectures.
Throughout my career designing high-scale cloud-native solutions, event-driven microservices, and modern data platforms, domain research, requirement validation, and exploratory design depended heavily on manual web searches, static documentation reviews, and disconnected whiteboarding sessions. Over years of hands-on practice, my workflow naturally evolved from manual research into AI-driven, interactive, and code-centric discovery. By leveraging AI coding assistants directly inside the development workspace to profile sample datasets, stress-test business rules, probe API interfaces, and validate system constraints in real time, I transformed traditional brainstorming into an active, deterministic engineering phase: AIStorming.
AIStorming formalizes the process of using AI coding tools (e.g., GitHub Copilot, Google Antigravity) to conduct real-time domain discovery, exploratory analysis, and system boundary mapping across both cloud-native software and data engineering domains. Rather than relying on abstract, non-executable IT discovery frameworks, AIStorming anchors domain analysis directly in executable code, version control, and data validation. This yields structured problem statements, refined use cases, quantifiable technical requirements, and machine-readable specifications optimized for vibe coding, cloud-native design, and automated SDD execution.

🚀 Featured Open Source Projects
Explore these curated resources to level up your engineering skills. If you find them helpful, a ⭐️ is much appreciated!
🏗️ Data Engineering
Focus: Real-world ETL & MTA Turnstile Data


🤖 Artificial Intelligence
Focus: LLM Patterns and Agentic Workflows

📉 Machine Learning
Focus: Introduction to machine learning

💡 Contribute: Found a bug or have a suggestion? Open an issue! and be part of the open source project.
1. The Core Engineering Challenge: The Discovery-to-Implementation Gap
In traditional enterprise software engineering, product discovery is often disconnected from actual system implementation. Product managers, business analysts, and architects spend weeks producing static requirements documents, wireframes, or text-heavy stories. When these artifacts are passed down to software engineers—or fed as prompt context into AI coding tools—the implementation breaks down due to implicit assumptions, unverified data schemas, unexpected edge cases, and missing operational constraints.
In an era dominated by AI-assisted synthesis, garbage context in results in garbage execution out.
+-----------------------------------------------------------------------------------+
| TRADITIONAL DISCOVERY GAP |
| |
| [ Domain & Business ] ---> ( Static Docs / Whiteboards ) ---> [ AI Assistant ] |
| Ideation & Concepts Unverified Context Hallucinated |
| Implementation |
+-----------------------------------------------------------------------------------+
VS.
+-----------------------------------------------------------------------------------+
| AISTORMING FRAMEWORK |
| |
| [ Domain Input ] ---> { AIStorming: Code-Centric Analysis } ---> [ SDD & Vibe ] |
| Raw Data / Rules / Exploratory Scripts, Profiling, Deterministic |
| API Contracts & Requirement Synthesis in IDE Builds |
+-----------------------------------------------------------------------------------+To leverage AI coding assistants safely and at enterprise quality, the Discovery Phase must be reinvented. It can no longer be a passive ideation exercise; it must become an active, code-centric discovery engine that validates domain facts, data structures, and service behaviors before full-scale software architecture and implementation begin.
2. What is AIStorming?
AIStorming is the process-oriented methodology of conducting domain discovery, exploratory data/logic analysis, and system boundary definition by pairing human engineering expertise with AI coding tools inside an Integrated Development Environment (IDE).
The objective of AIStorming is not to generate production application code or deploy live systems immediately. Instead, its primary output is a structured set of verified, code-grounded engineering artifacts:
- Grounded Problem Statements: Unambiguous scope boundaries, operational objectives, and domain invariants.
- Exploratory Data & Logic Findings: Code-verified insights into payload structures, edge cases, integration contracts, API behaviors, and processing constraints.
- Formal Functional & Technical Requirements: Explicit inputs, state behaviors, domain events, security boundaries, and non-functional targets (throughput, latency, reliability).
- Machine-Readable Specifications (SDD): Domain models, schemas, contract interfaces, and prompt-context files tailored for downstream vibe coding, agentic orchestration, and automated pipeline execution.
3. Foundational Principles of AIStorming
Derived from the universal tenets of my Data Engineering Process Fundamentals (DEP) and expanded across cloud-native software architecture, AIStorming adapts proven discovery mechanics to AI-driven developer tooling.
I. The Code-Centric Paradigm
Traditional discovery relies on prose descriptions that fail upon first contact with compiler logic, schema validation, or streaming engines. AIStorming dictates that discovery must be code-centric from day one.
- Exploratory data analysis (EDA), API probing, schema validation, and domain logic simulations are written as executable scripts (Python, TypeScript, SQL, Go, Jupyter Notebooks) inside the IDE workspace.
- AI tools are forced to interact with concrete execution outputs, stack traces, and SDK responses rather than abstract concepts.
II. Dataset & Domain Grounding
AI models hallucinate when operating in an isolated context vacuum. AIStorming requires immediate grounding against real-world sample datasets, schema definitions, domain models, and API interfaces.
- Evaluates data quality, structural variance, integration frequencies (batch vs. streaming event-driven), and service boundaries.
- Uses AI assistants to parse, profile, and transform sample payloads and domain entities live during the discovery window.
III. Source Control and Auditable Iteration
Prompt histories floating in web interfaces are disposable, non-reproducible, and unmaintainable. AIStorming enforces that every discovery artifact—exploratory notebooks, schema models, interface definitions, and context files—is checked directly into a Git repository (e.g., GitHub).
- Enables collaboration between software engineers, data architects, and AI agents.
- Maintains a versioned, auditable history of how business domain rules evolved into formal technical specifications.
IV. Bridge to Vibe Coding and SDD
AIStorming serves as the explicit precursor to Vibe Coding (rapid, intent-driven application development using AI models) and Software Design Description (SDD) generation. By translating loose ideas into code-verified constraints during AIStorming, downstream AI models receive high-fidelity, hallucination-free prompts during full-scale development.
4. The 4 Universal Steps of the AIStorming Process
Whether applied to cloud-native microservices, event-driven streaming applications, serverless architectures, or modern enterprise data platforms, the AIStorming framework executes across four process-oriented phases.
+-------------------+ +-------------------+ +-------------------+ +-------------------+
| STEP 1: | ---> | STEP 2: | ---> | STEP 3: | ---> | STEP 4: |
| Problem | | Exploratory | | Use Case & | | SDD & Vibe |
| Framing & | | Data & Domain | | Requirement | | Specification |
| Context Prime | | Analysis | | Synthesis | | Output |
+-------------------+ +-------------------+ +-------------------+ +-------------------+Step 1: Problem Framing & Context Priming
- Objective: Establish domain boundaries and prime the AI workspace with domain context.
- Process:
- Initialize a dedicated discovery branch in the code repository.
- Create a core workspace context file (
CONTEXT.mdor system prompt boundaries) containing raw business objectives, domain rules, SLA requirements, and target application guidelines. - Engage the AI coding assistant to challenge the problem scope, identifying missing assumptions, unstated edge cases, or domain contradictions.
Step 2: Exploratory Data & Domain Logic Analysis
- Objective: Verify domain facts and data behaviors using runnable code inside the IDE.
- Process:
- Load representative data samples, schema models, domain event payloads, or third-party API contracts into VS Code or Jupyter Notebooks.
- Pair with the AI assistant to write exploratory scripts using standard manipulation libraries, data frames, or contract interfaces (Pandas, Pydantic, Zod, Spark/PySpark, SQL).
- Perform data profiling, test payload transformations, inspect edge cases, validate event structures, and evaluate performance/throughput assumptions.
- Commit all exploratory scripts, test executions, and output traces to Git.
Step 3: Use Case & Requirement Synthesis
- Objective: Extract structured engineering requirements from discovery findings.
- Process:
- Prompt the AI assistant to analyze the commit history, exploratory scripts, and execution outputs generated in Step 2.
- Synthesize findings into formalized Use Cases (actor/system interactions, event triggers, preconditions, happy path flows, failover behaviors).
- Categorize non-negotiable Technical Requirements:
- Data Integration & Schema Transformation rules
- Cloud-Native Application Patterns (Event-driven, REST/GraphQL APIs, Pub/Sub boundaries)
- Performance, Scalability & Latency SLA targets
- Security, Identity, Governance, and Compliance boundaries
Step 4: SDD & Vibe Coding Specification Output
- Objective: Produce machine-readable software specifications for autonomous AI execution.
- Process:
- Compile discovery outputs into a standardized Software Design Description (
SPEC.md/ARCHITECTURE.md). - Generate baseline interface contracts, schemas, and domain types (TypeScript interfaces, OpenAPI specs, Pydantic data models, Avro/Protobuf schemas, ERD models).
- Define precise context prompts and agent instructions to drive subsequent implementation phases (Vibe Coding, Automated Test Generation, and CI/CD development).
- Compile discovery outputs into a standardized Software Design Description (
5. Architectural Deliverables Matrix
To maintain enterprise quality, an AIStorming session must terminate in a concrete set of repository artifacts:
| Deliverable Phase | File Artifact | Content & Purpose | Target Consumer |
|---|---|---|---|
| Problem Definition | PROBLEM.md |
Domain boundaries, business goals, explicit out-of-scope declarations | Lead Engineers & Architects |
| Exploratory Analysis | analysis/*.ipynb, scripts/* |
Executable data profiling, edge-case tests, API contract probes | Engineering Team & AI Agents |
| Use Cases | USE_CASES.md |
System interactions, domain event triggers, failure modes, retry logic | Product Owners & Testing Engines |
| Technical Specs | REQUIREMENTS.md, SPEC.md |
Data models, storage schemas, security boundaries, SLA performance targets | Vibe Coding AI Tools (Cursor, Copilot, Claude) |
| Architecture Contract | ARCHITECTURE.md, schemas/* |
System topology, ERD models, OpenAPI/AsyncAPI specs, CI/CD pipeline rules | SDD Generators & Developers |
6. Practical Application: Enterprise Cloud-Native & Data Platform Build
To demonstrate the versatility of AIStorming across cloud-native microservices and high-scale data platforms, consider the execution path of a modern enterprise solution:
- The Human Intent: An architect needs to design a high-throughput, event-driven data ingestion platform that processes live streaming payloads into an analytical data lake.
- The AIStorming Phase:
- Instead of asking an AI tool to "write a real-time data ingestion application," the team opens the IDE and loads representative stream logs and target schemas.
- The architect uses AIStorming to draft and run exploratory Python/PySpark scripts inside the IDE, testing deserialization speed, schema drift, and payload validation rules.
- The AI assistant identifies that 6% of incoming event payloads contain missing nested timestamp attributes and schema variations that would break downstream parquet writes.
- Requirement Synthesis: The team updates
REQUIREMENTS.mdvia AIStorming to explicitly mandate upstream payload sanitization, dead-letter routing (DLQ), and a strict contract enforcement layer. - SDD & Vibe Implementation: The resulting
SPEC.md, Pydantic models, and OpenAPI/AsyncAPI specs are fed into coding agents. The agents write production-grade microservices and pipeline code on the first pass because the domain edge cases were caught during AIStorming.
7. Conclusion: AIStorming as an Enterprise Engineering Standard
As artificial intelligence shifts software and data engineering from manual syntax writing to high-level system orchestration, the role of the engineer evolves from code writer to system architect and discovery strategist.
AIStorming bridges the foundational gap between raw domain ideas and deterministic execution. By marrying the process-oriented discipline of Data Engineering Process Fundamentals with cloud-native software architecture patterns and modern AI coding tools, AIStorming transforms discovery from a passive, unverified discussion into a repeatable, code-centric, and auditable engineering standard.
By adopting AIStorming as a formal phase prior to vibe coding and SDD execution, engineering organizations can eliminate AI hallucination risks, enforce enterprise domain integrity, and accelerate software delivery with complete architectural control.
References & Foundational Frameworks
- Garcia, Oscar D. (Ozkary). "From Raw Data to Roadmap: The Discovery Phase in Data Engineering Process Fundamentals." Ozkary Technologies
- Garcia, Oscar D. (Ozkary). "Data Engineering Process Fundamentals - Design and Planning."
- Garcia, Oscar D. (Ozkary). "Architecting an Agentic Data Pipeline - From Data Lake Discovery to Managed Orchestration."
🌟 Let's Connect & Build Together
Thanks for reading! 😊 If you enjoyed these resources, let's stay in touch! I share deep-dives into AI/ML patterns and host community events here:
- GDG Broward: Join our local dev community for meetups and workshops.
- Global AI Events: Join Global AI Events.
- LinkedIn: Let's connect professionally! I share insights on engineering.
- GitHub: Follow my open-source journey and star the repos you find useful.
- YouTube: Watch step-by-step tutorials on the projects listed above.
- BlueSky / X / Twitter: Daily tech updates and quick engineering tips.
👉 *Originally published at ozkary.com*